What is Index Maker

Index Maker is a Python script that semi-automates the creation of indexes for intranets and books-on-line. At the end of any paper-bound text book or reference book there is an index that tells where a particular word or topic is found. Intranets and business websites offen attempt to emulate this facility provinding a local search engine, mostly useless unless the costumers already know what to search for, or a map of the website, which is intimidating and seldom used.
Hence, the tool of choice of a website to guide a user to its destination is usually its tree structure. Still, it is not unusual for a user to spend a large amount of time traversing the tree, trying to find the location where the website stores what s/he is looking for: a driver, a document, a piece of data, a release note, etc.
Tree structures and maps that play the role of a table of contents can take us to the ballpark of the information needed. However, if we require specific information, we need an index, not a general table of contents which, by definition, is broad. An index has the right granularity to be the most likely to be useful to you. That is the functionality that we want to have.
There are only two tools to create indexes from online documents: HTML indexer, a commercial package that runs on Windows, and XRefHT, a freeware with versions for both Windows and Java. I think that a new program can easily make an impact in the area of indexing.
The target user for this application would be one that does not want to approach a large corporation like Google or Yahoo to create a simple index of their website but still sees the benefits of having it. Likewise, self-publishing authors like me could benefit of having such a program to aid in the otherwise hellish task of creating an index for an online book, which by its very nature, is dynamic changes everytime that a change in the text is made.
Block diagram of Index Maker
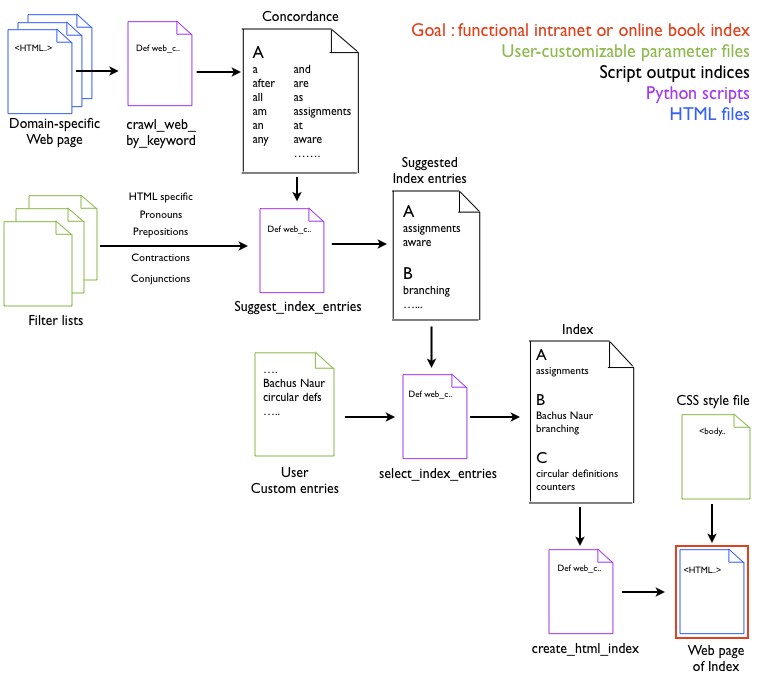
Index Maker is composed of four functions, shown in purple in the block diagram:
- Crawl_web_by_keyword
- Suggest_index_entries
- select_index_entries
- Create_html_index
The inputs to these functions are parameter files (shown in green) that can be modified by the user and the online html files that are being indexed (shown in blue).
The output of the four routines, shown in red, is an HTML file ready to be uploaded to the website.
Ideally, the user would have had access to the parameter files via a GUI or, even better, a web page, but this is not set up yet.
The following is a brief description of the four main functions.
crawl_web_by_keyword
The starting point for this routine is a web crawler adapted to crawl a specific set of pages defined by white and black lists. For example, to index a book we might have:
- white_list = {"mybook", "chapter"}
- black_list = {"copyrights", "glosary"}
In the event that the pages that the user wants to index are disjointed and cannot be crawled from a single parent, the user can instead write the list of urls that need to be indexed.
The output of this function is a type of index commonly known as a "concordance", i.e., an index that contains every single string found. This is a problem because, although a search engine will return a valid result to an arbitray query, i.e., "a", "as", "at", an index should not.
suggest_index_entries
This function sieves the concordance produced by the web crawler into a small set of words that are likely to be pertinent. In the tests that we ran, it is usual to have a reduction number of words from the concordance to the index of the order of 2-to-3, i.e, if the concordance had 3000 words, the index of suggested words has about 1500-1000 words.
This filtering process is automatic. The function receives as input a number of files containing words that are likely to not belong in an index, e.g., pronouns, conjunctions, prepositions, contractions, common verbs, etc. The user can decide which filters to use or add his/her own, for example, for localization.
The output of this function is the index of suggested entries.
select_index_entries
This function uses the index of suggested entries as the starting point to obtain a final index. This step is important because the program is not capable to measure the importance of combination of words. For example, "monty" and "python" might be relevant but "monty python", as a combination, has a different connotation. Also, the program is bound to omit words that the user considers important and to add words that the user does not care for.
The function allows the user to alter the suggested entries in two ways. First, the user can set white and black lists of entries that specify words or word sets that the users want to have or to omit respectively.
For example, if the words "Albert" and "Einstein" are in the suggested word list, it would be reasonable to black list "Albert" and white list the combination "Albert Einstein". In this way both "Albert Einstein" and "Einstein" would be entries but "Albert", by itself, would not.
The merging of the white and black lists with the suggested words happens automatically, after which the user is allowed to interact with the list and add or remove words or combinations of words on the fly.
The output of this function is an list with the words that will be in the online index.
create_html_index
This final function makes a web page using the list of words that we selected. The web page is ready to put online. By default, it is a strict XHTML 1.0 page in the english language that could pass any validation test with a good grade.
The appereance of the page can be changed by hand, modifying the html page or, without altering the page by modifying a CSS file.
